

Picture a stop-and-go conveyor line: the conveyor halts, every robot on the line deposits its ingredient, and once all of them are done, the conveyor companion box signals the conveyor to move again. This process repeats hundreds of times per shift. It sounds mechanical and predictable, and it is… until you need to test it without the hardware it runs on.
Chef’s conveyor companion box is an industrial PC (IPC) that sits alongside a customer’s conveyor controller, reads its digital and analog I/O, and communicates with every robot module via Transmission Control Protocol (TCP). On stop-and-go conveyor lines, it acts as the coordination layer for the entire indexing cycle, telling the conveyor when to stop, waiting for all robots to finish their deposits, and signaling it to move again.
Before the conveyor companion box existed, there was no way to run the full stack—the runner, the per-cycle handshake, and multi-module coordination—without physical hardware.
We’ve now fixed this issue by adding a hardware abstraction layer (HAL) to the runner and building an in-process emulation driver that simulates an industrial PC (IPC) and models the customer conveyor programmable logic controller (PLC). Now, the complete indexing stack can run on a developer laptop with zero hardware in the loop.
The problem: Testing conveyor logic requires an industrial PC (IPC)
While the companion box coordinates the indexing cycle reliably in production, testing the deposit-and-go sequencing logic was a different problem entirely. Getting it wrong—a missed acknowledgment, an off-cadence cycle, or a synchronization race between modules—means trays move before deposits are complete, or robots wait indefinitely for a go signal that never comes.
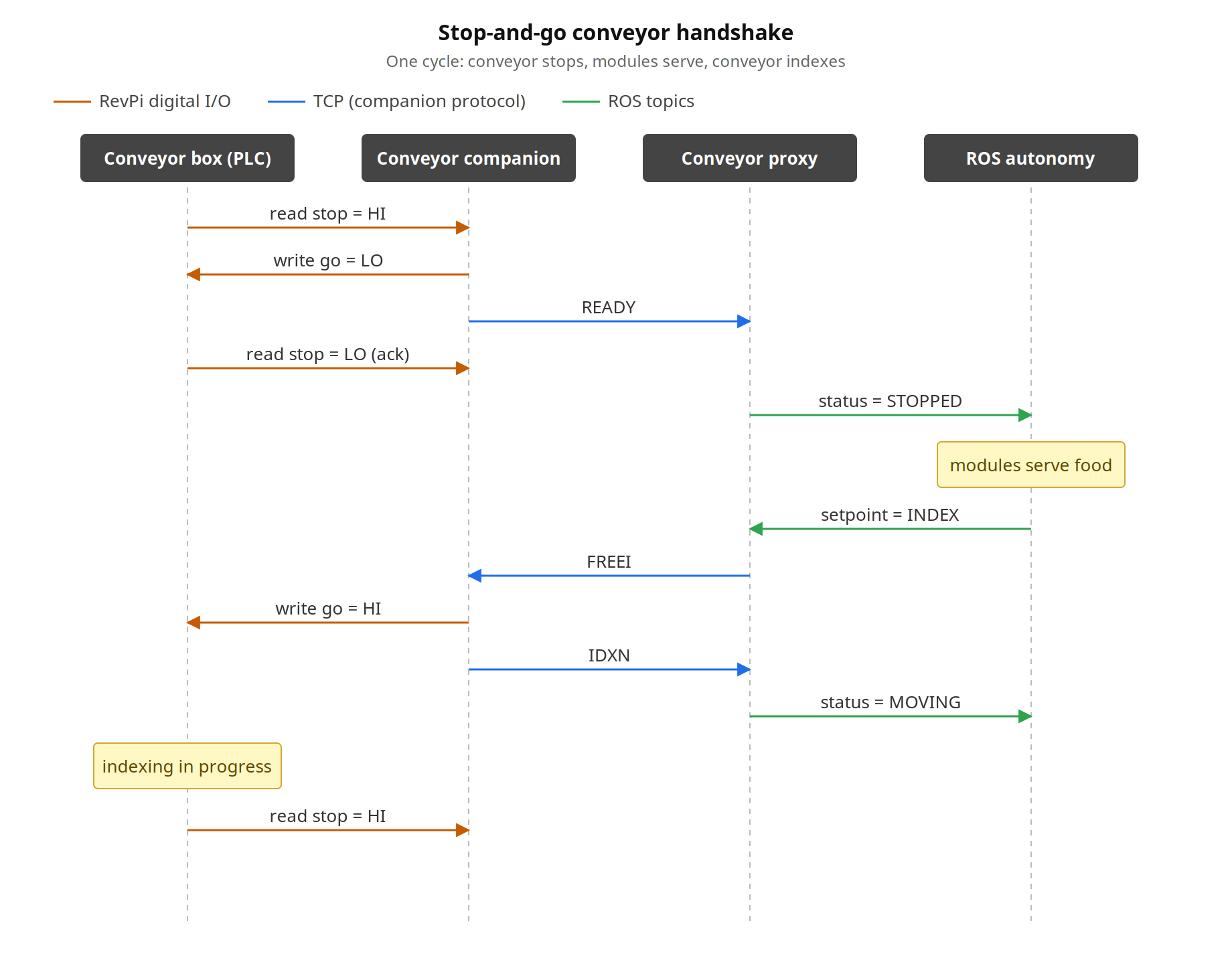
Figure 1. The indexing cycle. The emulator must reproduce one full deposit-and-go sequence end-to-end.
We had two ways to test this logic. Neither covered the full loop.
- Unit tests exercised the application classes against in-process fakes. But they never ran the runner, the cycle loop, or the network server—the parts where timing and coordination bugs actually live.
- A manual hardware-in-the-loop (HIL) workflow deployed an emulated PLC variant of the app to an industrial PC (IPC), allowing an engineer to monitor cycles via a command line interface. It was an operational procedure rather than an automated test, and it still required an industrial PC (IPC).
The consequence was a class of bugs that could only be reproduced with hardware: multi-module synchronization races, off-cadence cycles, stop-clear ack handling gone wrong. These bugs were hard to catch on a laptop or in continuous integration (CI). They only surfaced on a live line.
The root cause: Two layers of hardware coupling
Our runner’s dependence on IPC (we currently use RevPI but are agnostic) hardware had two independent layers, and we had to break each one separately.
- I/O coupling: The runner instantiated revpimodio2.RevPiModIO directly relied on its cycle-loop API to drive every tick. Any test path had to either provide an industrial PC (IPC) or completely duplicate the runner. Neither was acceptable.
- Controller coupling: Even with fake I/O, the application sits idle forever unless something plays the role of the customer’s PLC: toggling the stop input active when the conveyor halts, dropping it again once the box answers with go=LO, and re-asserting it after the index completes. None of our existing infrastructure modeled that loop. The application had no counterpart to talk to.
These two problems—the I/O dependency and the missing controller model—had to be solved together. Fixing one without the other still left the stack unable to run end-to-end.
Our approach: a HAL and an in-process PLC model
Our solution has two parts, one for each layer of coupling.
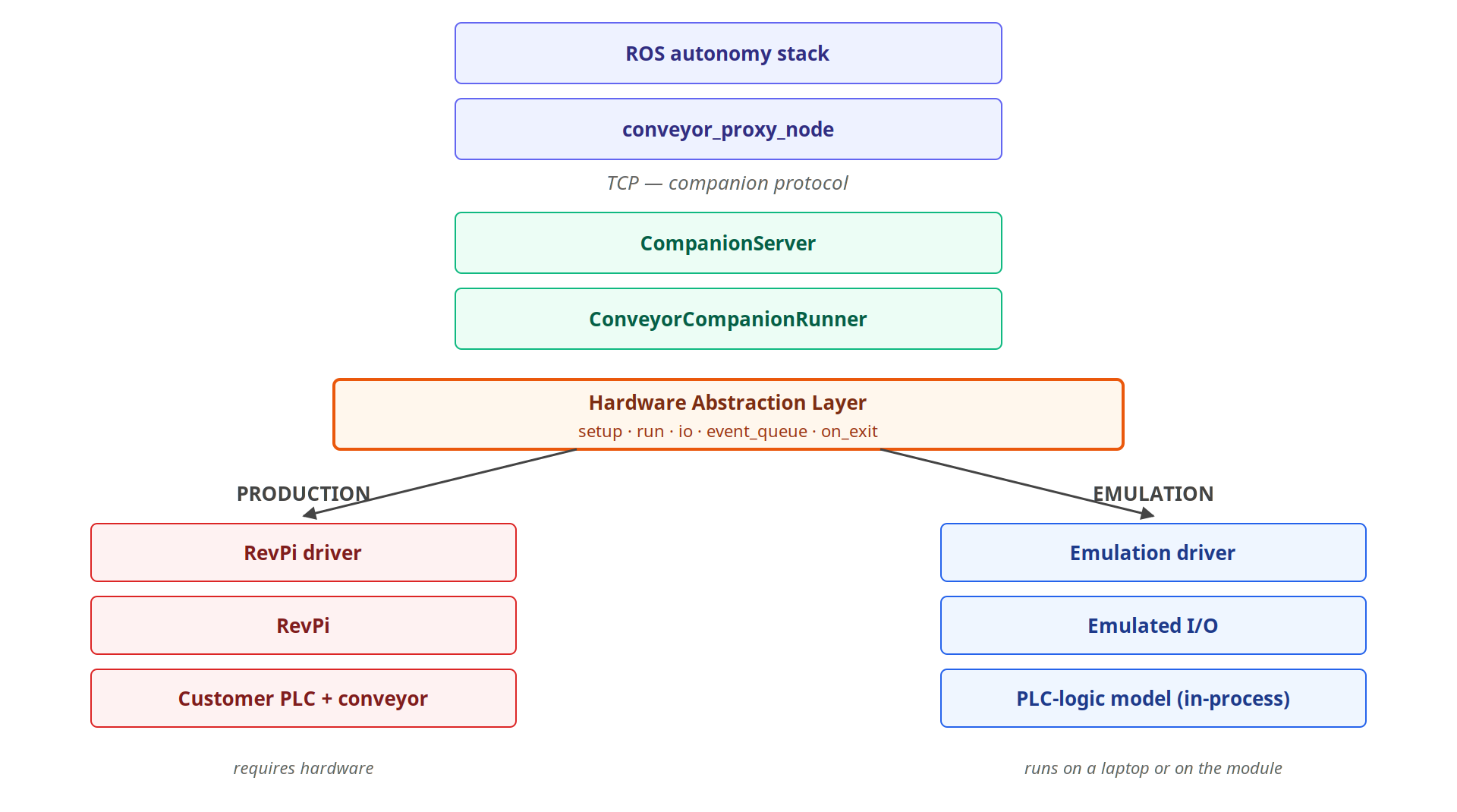
Figure 2. HAL seam. Everything above the seam is identical in production and emulation; only the driver below is swapped at startup.
Extracting the hardware abstraction layer (HAL)
We defined a small structural interface—setup, run, on_exit, plus io and event_queue accessors that capture exactly what the runner needs from the driver, and nothing more. The production driver becomes a thin adapter over revpimodio2.RevPiModIO. The emulation driver becomes a peer implementation that fakes the same surface.
The key property of this seam is that everything above it—the network server, the per-line apps, the message queues, and the 50 ms cycle loop runs unchanged in both modes. Production and emulation share the same runner, not parallel versions.
Modeling the customer PLC
The second part was StopAndGoPlcLogic: a minimal model of the customer controller that runs inside the emulation driver. It ticks at the same frequency as the application above it and advances the PLC state machine, toggling the stop input active when the conveyor halts, dropping it again once the box replies, and re-asserting it after the index. Cycle parameters live in an ordinary dataclass. This is what makes the conveyor appear to “stop” and “go” to the application above without any external process driving it.
The trickiest part: preserving the I/O event contract
Our applications register edge-triggered handlers (rising, falling, or both) that fire between cycles rather than from interrupt context. The stop-and-go state machine drives two such handlers. Any deviation in callback timing corrupts the cycle.
Our emulated I/O layer mimics this with a value setter that detects the edge and enqueues matching callbacks onto a shared event queue. The runner drains that queue on every tick before ticking each app, exactly what the production cycle loop does, so the runner never has to know which driver it’s talking to. Get this wrong and the state machine stalls; the cycle never completes. Get it right, and the behavior is indistinguishable from hardware.
Why did we use a HAL rather than a second entry point
A simpler approach would have been a second entry point that wires up fakes specifically for indexing tests. It would have worked in the short run. We chose the HAL instead for three reasons:
- No drift: A single main loop means production and test code paths never diverge as fixes land. With a second entry point, a bug fix in the runner must be manually mirrored to the test path, or the test becomes stale without anyone noticing.
- Single source of truth: Multi-config and IP/port validation logic lives in one place rather than being maintained in two independent entry points.
- Future-proof: New drivers—non-industrial PC (IPC), additional emulators, and CI-specific variants plug in at the same seam. The runner doesn’t change.
This approach required us to write more code up front, but it turned out to be the only option that scales to multiple alternative drivers without forking the runner.
Results
The qualitative result of our approach is that every layer above the HAL seam—the runner, the network server, the apps, and the cycle loop—now runs unmodified on a developer laptop or on the module itself, with no physical hardware required. This means:
- The full indexing cycle executes against an in-process PLC model. No industrial PC (IPC). No physical conveyor.
- The single decision point that selects between hardware and emulation is one if branch in main.py.
- Synchronization races, off-cadence cycles, and ack-handling bugs that previously required a live line to reproduce can now be caught on a laptop before a single line of code ships to a customer site.
Takeaway
When end-to-end testing is blocked by hardware, the right place to cut is the production runner, not the test path. A small HAL and a minimal in-process PLC model moved our full companion stack into the same fast feedback loop as the rest of our autonomy code, without forking the runner or losing fidelity at the wire protocol or per-cycle handshake.
As we deploy to more customer sites with different conveyor configurations, that feedback loop matters more, not less. The emulator automatically grows with the production reference implementation because they are the same code.
Curious about how we build reliable robotics software for real production environments? Get in touch with our team.
%20copy.png)

.png)