Introduction
At Chef Robotics, we’re on a mission to put an AI-enabled robot in every commercial kitchen in the world. One of the biggest hurdles to this mission is the pace at which we onboard new foods. Each food item we handle has unique customer requirements and physical properties, and thus requires unique motions. For instance, a spoonful of sticky mashed potatoes may need a well-timed flick of the wrist, but the same motion for a ladle of pasta sauce would result in the production floor looking like an NCIS crime scene.
Traditionally, our robot’s motion planning & control stack operates with four basic components:
- Perception: Process camera images to determine the position and velocity of bowls on the conveyor.
- Path Planner: Construct a Plan (low frequency sequence of end effector waypoints for time) from a finite set of user defined parameters such that the robot’s end effector reaches a bowl at the right time and location.
- Trajectory Planner: Using inverse kinematics, derive Joint Trajectories (high frequency sequences of joint angles in time) which drive the robot’s End Effector through the waypoints specified in the Plan.
- Controller: Using a real-time closed-loop feedback controller, set an appropriate motor voltage for each joint to follow the provided Joint Trajectories.

This paradigm of motion planning was derived from industrial robot arms, where precision and speed are of utmost importance. However, the process for developing new parameterized motions can be slow and resource intensive, often taking months of engineering effort to develop and refine a single motion. In particular, this approach is brittle in environments where the characteristics of the items your robot is manipulating are not highly controlled. Unlike car doors on an assembly line, subsequent batches of a particular food may vary greatly in density, particle size, or stickiness. Due to these variations, a motion that worked well for a particular food on Monday may perform very differently on Tuesday.
Recent advancements in Imitation Learning (IL) stemming from breakthroughs with diffusion models offer a promising alternative, where robots can learn from human demonstrations rather than relying on hand-coded motion parameters. By capturing human intuition and skill, this new approach enables rapid onboarding of new foods without any engineering involvement, drastically reducing development time while improving the system’s ability to adapt to the ever-changing characteristics of food.
System Design
Our implementation adapts Chi et al.’s work on Diffusion Policy to create a drop-in replacement for the previous Path Planner component of Chef’s Motion Planning & Control stack. Diffusion Policy brings the same diffusion neural networks used in DALL-E or SORA to the physical world by adapting the network to predicting end effector poses instead of pixels. We built on this approach by:
- Extending the action space to a quaternion from 2D coordinates to enable inference transformation to a 3D Path.
- Add a 2 second planned path horizon as an input to the model to enable merging of subsequent paths.
By focusing on end-effector waypoints as a model output instead of joint trajectories, we retain human interpretability, making it easier to analyze and debug the system’s behavior. Additionally, this approach preserves a clear separation between high-level motion intent (determined by the diffusion model) and low-level execution details (handled by the trajectory planner), simplifying system integration and maintenance.

Data Collection
To ensure that our motion demonstrations were both easy for the model to learn from and transferable to our robot’s form factor, we needed a data collection system that met three key requirements:
- Kinematic Grounding – All recorded motion paths must be achievable within the kinematic constraints of a Chef robot.
- Unoccluded Camera Views – Recorded training data must be free from obstructions caused by human operators, in order to match real-world operation.
- Physical Validity – Demonstrations must have real-world interactions between the end-effector and food, ensuring that learned motions accurately reflect the complex physical interaction between food and end-effector.
After evaluating multiple data collection strategies, we implemented a Leader-Follower Teleoperation approach inspired by ALOHA, as it was the only method that satisfied all three criteria. See the table below for an overview of the trade-offs between different strategies we considered.

The Leader-Follower Teleoperation approach ensures kinematic feasibility, unoccluded camera views, and physical validity by allowing an operator to control a leader arm, which a follower arm mimics in real time. Since this setup runs on real Chef hardware, all recorded demonstrations are guaranteed to be kinematically feasible, and can be directly executed by the robot. Since the operator only interacts with the leader arm, the follower arm records data exactly as it would in a production environment, eliminating the need for post-processing to remove human hands or body parts from the dataset.
Additionally, this method ensures physical validity through real-world interaction between the end-effector and food, capturing the natural forces that influence food placement. As an added benefit, operators receive direct kinesthetic feedback, allowing them to intuitively refine motions, resulting in more efficient and naturalistic demonstrations.
Teleoperation using the Leader-Follower System
To implement Leader-Follower Teleoperation, we use the following system setup:
- Leader Module: The leader module operates in Freedrive mode, with the leader’s end-effector pose broadcast to the follower via ROS.
- Follower Module: The follower module runs an end-effector pose controller to precisely track the leader’s movements in real-time.
- Data Recording & Cloud Upload: During demonstration collection, operators control a data recorder on the follower module, ensuring that only relevant timespans are captured. All recorded demonstrations are automatically tagged and uploaded to the cloud for storage.
This streamlined pipeline allows us to rapidly gather high-fidelity demonstrations, providing the data needed to train our diffusion based Path Inference model.

To build a model that generalizes well to real-world conditions, we needed a training dataset that captured the full variability of our operational environment. To achieve this, we parameterized the environment into eight, easy to control factors:
- Number of Bowls
- Bowl Type
- Bowl Location
- Bowl Orientation
- Bowl Fill Level
- Conveyor Speed
- Conveyor Direction
- Conveyor Messiness
During data collection, we monitored the distribution of each parameter in our dataset and opportunistically sampled demonstrations to ensure a balanced representation across different conditions. If testing revealed weak performance on a specific parameter or combination of parameters, we could quickly re-sample demonstrations to correct imbalances and improve model generalization.
To further enhance robustness, we added a small set of demonstrations with human disturbances, such as removing or repositioning bowls, helping the model learn to adapt to unexpected changes in its environment. This iterative data collection process ensured that our trained model is resilient to real-world variability and capable of handling the dynamic nature of commercial kitchen operations.
Training
After collecting hundreds of reference demonstrations, the next challenge was transforming raw ROS bags into a structured training dataset suitable for our Imitation Learning model. This started with careful curation to ensure the model learned from high-quality demonstrations. We manually reviewed the video feed from each demonstration to remove examples that were too slow, spilled during transit, or missed the bowl entirely. After review, satisfactory demonstrations were cropped to eliminate idle time with the robot lingering at a single pose between demonstrations.
Another key challenge was downsampling recorded trajectories to match the desired prediction frequency and horizon. With image frames recorded at 6Hz and end-effector poses at 50Hz, we had to resample the dataset to a uniform 5Hz frequency for consistency with our model’s expectations. Finally, we converted all processed data from ROS .bag format to .zarr for efficient storage and retrieval during training. These preprocessing steps were essential for optimizing dataset quality, leading to more stable and reliable model performance.
Sample of Processed Scooping Dataset
We started off training our model using a single A100 GPU hosted on Google Cloud Platform (GCP), but this approach quickly proved inefficient. It took over two days of training for the model's loss to decrease enough to warrant evaluation. Combined with availability issues with A100 equipped cloud VMs, our iteration speed was severely limited. Upon analysis, we found that our training was bottlenecked by batch loading time, making it CPU-bound rather than GPU-bound. But, with the large diffusion model we had to strike a careful balance between sufficient GPU memory to fit the model and vCPU cores to ensure rapid batch loading. We needed to find a training configuration that optimized for speed while ensuring access to the necessary hardware.
To address these challenges, we switched to a distributed training setup, optimizing for maximum CPU cores per GPU while ensuring the GPU had sufficient memory for the model. Our final training configuration used 8x L4 GPUs with 96 vCPUs, significantly decreasing batch loading time by increasing the number of concurrent workers. With this new configuration, training time dropped from days to just 12 hours—allowing for daily iteration on new models and accelerating our development velocity.
Inference
Our prototype system consists of several key components working together to generate and execute learned motion trajectories. Current images from each of the Chef module’s two RGB-D cameras, along with the previous second and next 2 seconds of the current path, are sent to a Path Inference component. The Path Inference component then produces a new Predicted Path extending 4 seconds into the future. To account for inference latencies, the Path Planning module intelligently merges the new predicted path with the current path, enabling a single continuous, smooth motion. The Trajectory Planning module then converts this refined path into low-level joint commands, which are executed by the Control system to move the robot.
To enable smooth, continuous real-time control, we had to innovate beyond the single-shot inference and execution approach used in the Diffusion Policy paper. With our model running inference at ~2Hz, we found that the robot would deviate significantly from its initial pose during the ~500ms delay from inference call to prediction return. This led to jerky motions, with the robot “jumping back” to repeat sections of the path it had already traversed when new predictions arrived. To ensure smooth motion, we had to figure out how to smoothly transition between the previously planned path and the newly predicted one.
To address this, we incorporated 2 seconds of the existing planned path as an input to inference, ensuring that the model generates predictions that overlap with the current trajectory rather than diverging sharply. Additionally, we introduced a path merging algorithm, where the robot blends from the current path with the predicted path at a point 0.5 seconds in the future, maximizing the likelihood of alignment and ensuring smooth, uninterrupted motion. In the gif below, you can see the output of this path merging algorithm with the robot’s future path (green line) and end effector waypoints (purple arrows) updating as new path predictions are received.
Visualization of Continuous Control with Imitation Learning
These innovations significantly increased execution speed and motion fluidity, allowing our robotic system to respond dynamically to changing environments while maintaining stable and predictable behavior.
Case Studies: Learning Novel Tasks
Case Study: Scooping
One of the more challenging motions for our robots is scooping, a critical skill for handling bulky, hard ingredients like frozen broccoli or shrimp. Our traditional path planning approach has struggled to produce effective scooping paths due to the fluidity of a motion required to properly lift food onto a utensil without excessive spillage or incomplete pickups. Successfully implementing a robust scooping motion would unlock a broad class of ingredients that Chef’s current motion planner cannot handle, significantly expanding the system’s capabilities and the company’s prospective customer base.
Our onboarding loop for scooping consists of three iterative phases: data collection, training, and testing. Using our Leader-Follower Teleoperation setup, we collected hundreds of scooping demonstrations within just a few hours. The collected dataset was then reviewed, post-processed, and loaded onto our distributed training cloud VM to train overnight. The next morning, we deployed the model to our in-house modules and observed both successful and failed execution attempts. Failures were carefully analyzed to identify gaps in the training data, prompting re-sampling of edge cases before repeating the loop. Through this process, we rapidly refined the model, steadily improving the robot’s ability to scoop food with the precision and consistency required for real-world deployment.
Here’s a snippet of the system running fully autonomously, in real-time with bowls at different distances and angles:
Realtime, Autonomous Execution of the Scooping Task
In addition to a much faster onboarding workflow, the system also proved capable of handling a variety of scenarios not present in the training dataset.
Placement in Square Bowl
Placement in Round Bowl
Responding to Removed Bowl
Reversed Conveyor Direction
Case Study: Spreading
To validate the extensibility of our Imitation Learning approach, we applied it to a second task: spreading mayonnaise on sandwich bread. Spreading mayonnaise requires a complex motion with many difficult to model rotations, as well as precise end effector positioning to achieve an even spread. Under a traditional motion planning paradigm, this motion would take months of dedicated engineering effort to develop. Using our Leader-Follower teleoperation approach, we were able to collect an initial training dataset over the course of a single afternoon.
Sample of Processed Spreading Dataset
Once the data was collected, we were able to post-process and complete training overnight using our multi GPU-equipped cloud VM for distributed training. The next day, we were able to test the trained model in-house, identify failure cases, and resample scenarios. With only a few days of repeating this process, our system was capable of autonomously spreading mayonnaise on sandwich bread.
Realtime, Autonomous Execution of the Spreading Task
Just like the scooping model, the spreading model showed a remarkable ability to recover from disturbances such as a poor initial spread.
Spreading Model Responding to a Poor Spread
In under a week, and with zero new lines of code, this system was able to learn an entirely new task that would have previously taken months and thousands of lines of code. This rapid onboarding cycle validates our vision of reducing motion development time from months to days, proving that our approach can generalize beyond a single skill and be applied seamlessly to new culinary tasks.
Towards a General Purpose Food Manipulation Model
Our work on Imitation Learning for culinary automation has proven the feasibility of a new paradigm for robotic motion development, drastically reducing the time required to onboard novel tasks. By replacing months of rule-based motion design with a data-driven, demonstration-based approach, we’ve taken the first steps toward a future where Chef Robotics can deploy new skills in days instead of months.
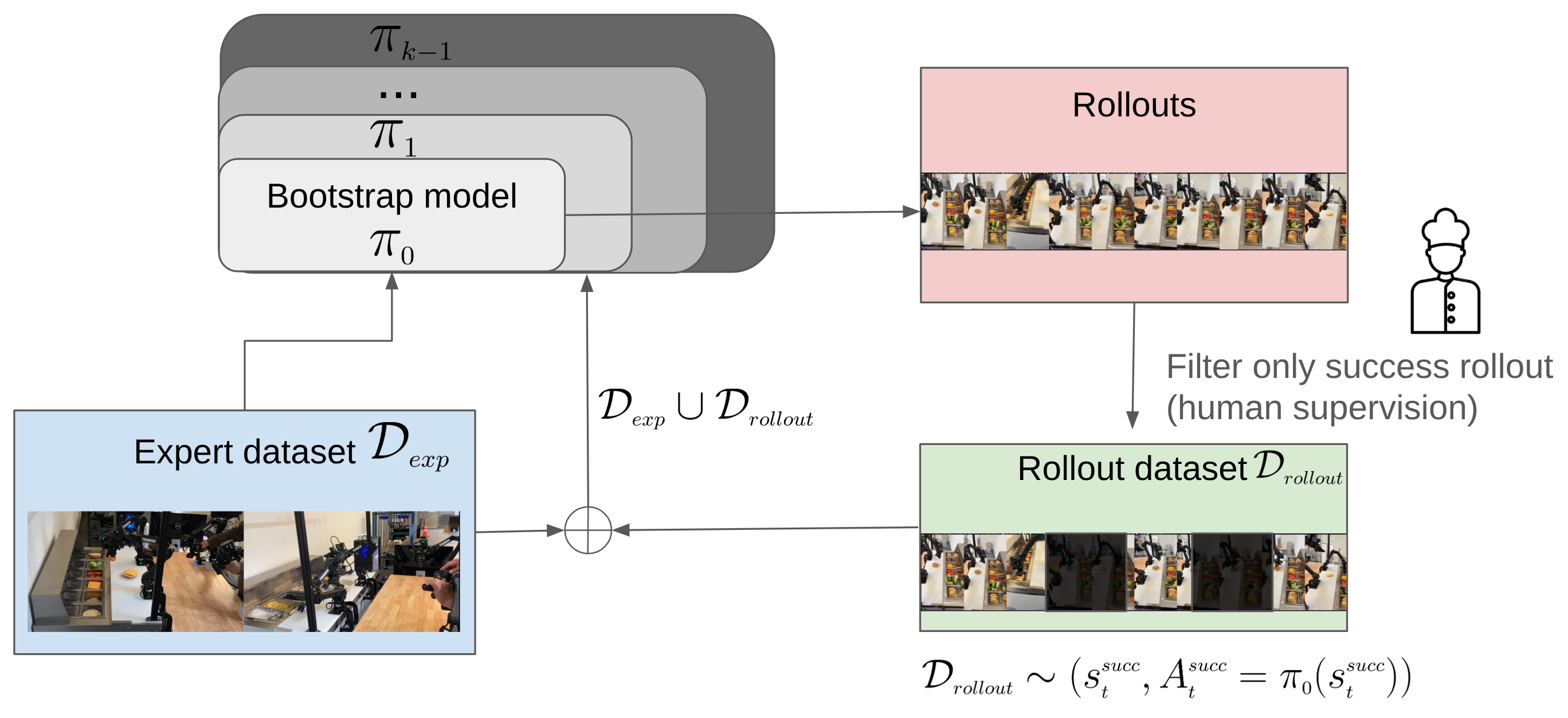
While Imitation Learning is a powerful tool for rapid motion onboarding, it alone is not sufficient for production-grade performance. The effectiveness of an Imitation Learning-based system is fundamentally limited by demonstration quality, meaning performance is capped by human teleoperation skill. This becomes especially problematic when customer requirements demand precision beyond human capability, such as achieving highly consistent deposit weights. Additionally, Imitation Learning struggles to anticipate rare failure cases and edge conditions that arise in real-world kitchens, where food products, bowl types, and environmental conditions vary unpredictably. To scale AI-driven culinary automation, robots must not only learn from human demonstrations but also improve beyond them.
To achieve super-human performance, Chef is developing a self-learning, general-purpose food manipulation system. We begin by bootstrapping models with human demonstrations, enabling robots to quickly acquire baseline competency for novel tasks. Once deployed in real production environments, these robots continuously collect and learn from real-world data, capturing variations and edge cases that human operators might not anticipate. Learning from human demonstrations is just as important as learning from production demonstrations, allowing our system to bridge the gap between human intuition and real-world execution.
To push performance beyond human-level execution, we next integrate offline reinforcement learning, fine-tuning models to optimize for specific customer requirements like precision or speed. These improved models are continuously redeployed, creating a self-improving feedback loop where robots not only learn from operators but also refine their skills through real-world experience. This iterative learning system is key to achieving fully autonomous, high-performance food manipulation at scale, bringing us closer to a future where AI-driven robots seamlessly handle food preparation across commercial kitchens worldwide.

This milestone marks a major step forward in Chef Robotics’ mission to place AI-enabled robots in every commercial kitchen. By combining Imitation Learning with reinforcement-driven self-improvement, we are building a future where robots continuously expand their capabilities without extensive engineering effort. If you’re excited about solving real-world challenges at the intersection of robotics, AI, and food, we’re hiring! Join us in shaping the future of culinary automation—check out our careers page to learn more.
Acknowledgements: We are grateful for all who contributed including Gabe Rodriguez, Somudro Gupta, C.J. Geering, Norberto Goussies, Luis Rayas, Vinny Senthil, and Dean Wilhelmi

.jpg)