
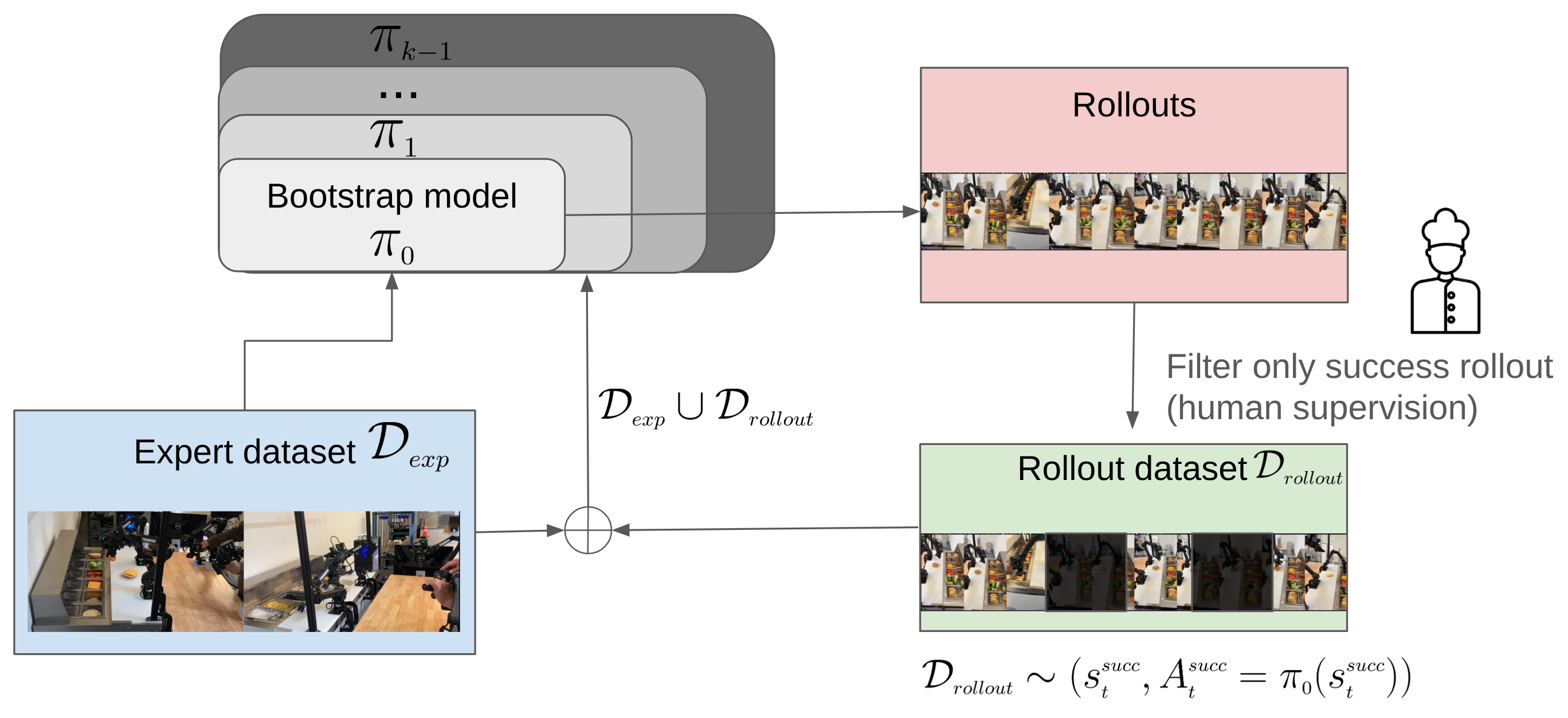
The data flywheel in one picture: train a deep learning model on human demonstrations, run it on our physical AI system, keep only the successful runs (with light human supervision), fold them back into the training set, and retrain. Each turn feeds the model more of what it actually sees on the job.
In part 1 of our blog series on our general-purpose physical AI system for food manipulation, we described how we trained a bi-manual system to assemble a burger in less than a minute and reported a 75% success rate. Part 2 showed how we trained the same system to make a burrito bowl. Part 3 of this blog series now returns to the burger assembly task, exploring how we improved our system’s performance by using better training data.
By adding 4.5% more training data to our physical AI model for burger assembly, we improved its success rate from 75% to 91.3%—without adding any new architecture, a bigger model, or extra hours of demonstrations. This 16% improvement is the result of a single iteration of a loop we call the data flywheel. Every successful run our system completes becomes training data for the next version of our physical AI model. It is built to keep running.
The gap between learning and deployment
For the burger assembly task, we start by training our physical AI model using human demonstrations: operators guide both arms through the full burger assembly sequence, and the model learns from these recordings. Our dataset holds 1,249 human demonstrations. Our physical AI system then runs under different conditions than the ones the model was trained on—the lighting shifts, ingredients are staged differently, and the system reaches joint configurations that no human demonstration has covered.
When the system enters an unfamiliar state, a problem known as covariate shift occurs. The system has no reference to follow, and small errors compound across many sequential decisions. In our baseline tests, the drop in success rate shows up most on cheese and lettuce placements, the most difficult steps, while bun placement stays reliable.
To solve this issue, we decided to train our physical AI model not only on demonstrations but also on data from burger assembly runs our system has successfully completed.
An iterative deep learning model
We build a training loop in which our system’s successful runs feed back into the next round of training. The loop works as follows:
- Run: Deploy the current physical AI model on the system and record every attempt.
- Filter: Keep only data from successful runs. For the burger assembly task, we keep the runs in which all six ingredients (bottom bun, patty, cheese, tomato, lettuce, top bun) are placed correctly on the first try without any retries. A human supervisor reviews and filters each run.
- Retrain: Add the filtered runs to the original demonstration dataset and retrain the physical AI model.
- Repeat: Each cycle adds more examples of the conditions the robot actually encounters in production.
We call this iterative deep learning (i.e., iterative rejection sampling fine-tuning). This blog covers one complete cycle of the flywheel.
Results from one cycle of the flywheel
The physical AI model trained on 1,249 human demonstrations achieved a 75.0% success rate across 20 trials. After running the model on our physical AI system, filtering for successful runs, and adding 56 successful runs back into the training set—approximately 4.5% more training data than we used previously—the retrained physical AI model achieved a 91.3% success rate across 80 trials.
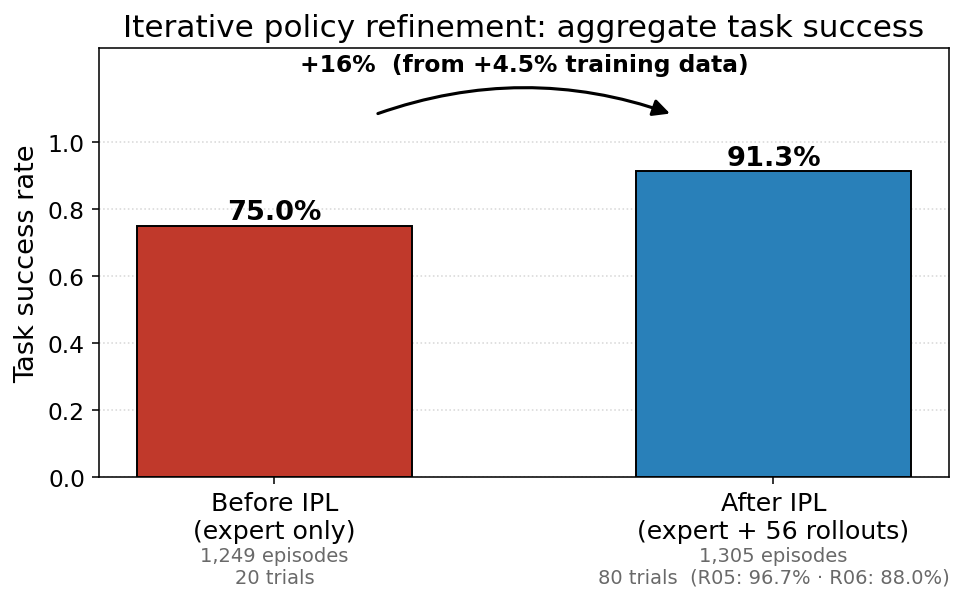
Even though we only added 4.5% more training data, we saw a 16-point improvement in our system’s success rate on the burger assembly task. Why?
Why does so little training data have a large impact?
The reason for our system’s improved success rate isn’t the quantity of training data but the quality. When our physical AI system carries out a task trained exclusively on human demonstrations, the production conditions (i.e., the exact visual and physical states it encounters) differ from the situations our model was trained on. By recording 56 successful burger assembly tasks and adding that data back into our model for training, we not only make our training dataset larger but, more importantly, address the specific details our system would struggle with if trained exclusively on demonstrations.
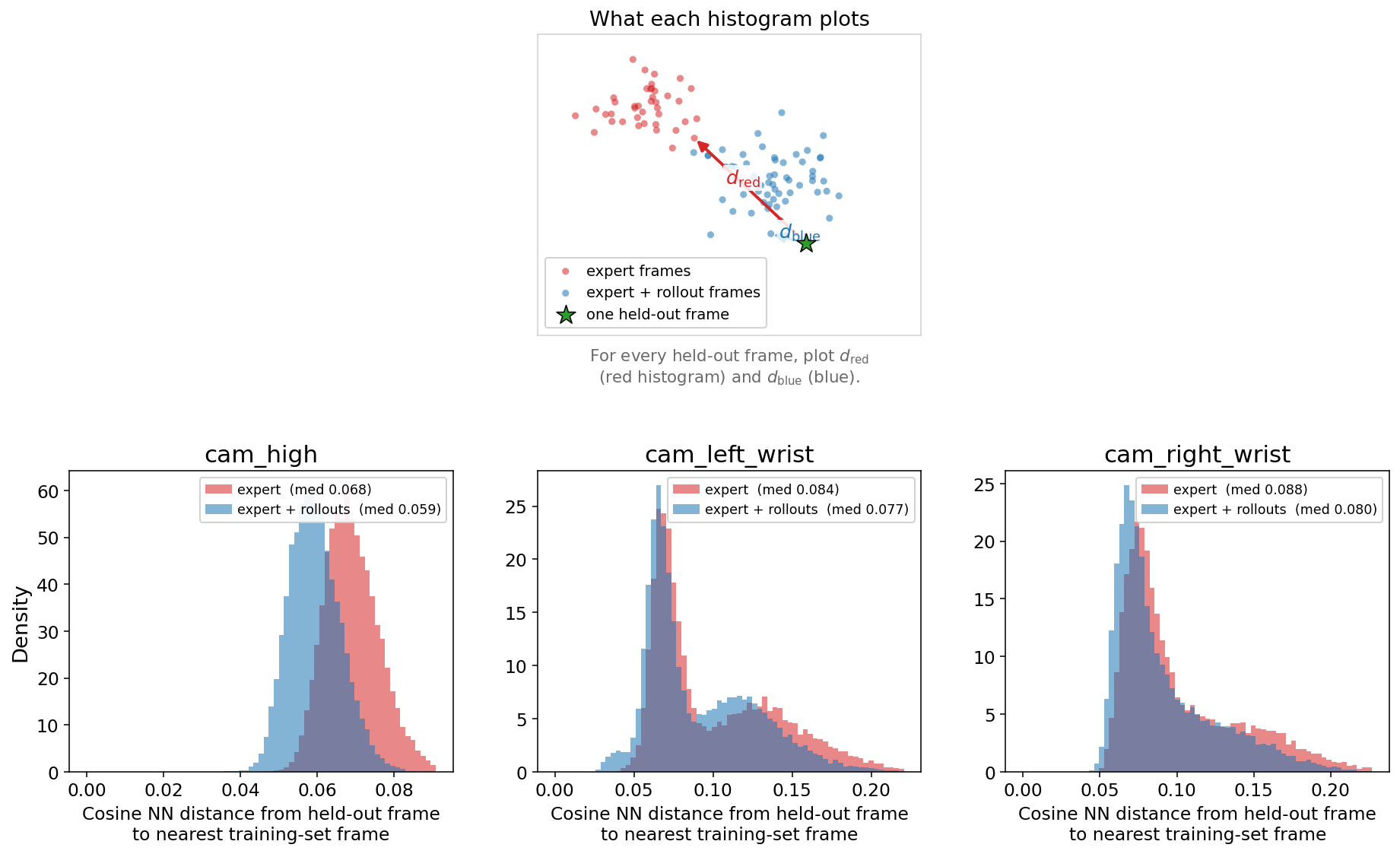
To understand this further, we look at how closely our system’s data captured during burger assembly runs matches its training data. For every camera frame captured during deployment, we calculate its distance to the nearest frame in the training set using cosine distance between frame embeddings in the DINOv3 ViT-B/16 feature space (768-D), rather than over raw pixels. After adding the system’s successful burger assembly runs to the training data, the distances decrease across all three cameras. The same pattern appears in the arm’s joint movements: when training on successful runs, the arm positions reached during a future run are measurably closer to the training data, most notably for cheese and lettuce placement.
The same pattern appears in a 2D projection of the camera frames, where similar-looking frames cluster together. Our system’s own successful runs land among the held-out deployment frames, while many human demonstrations sit apart.
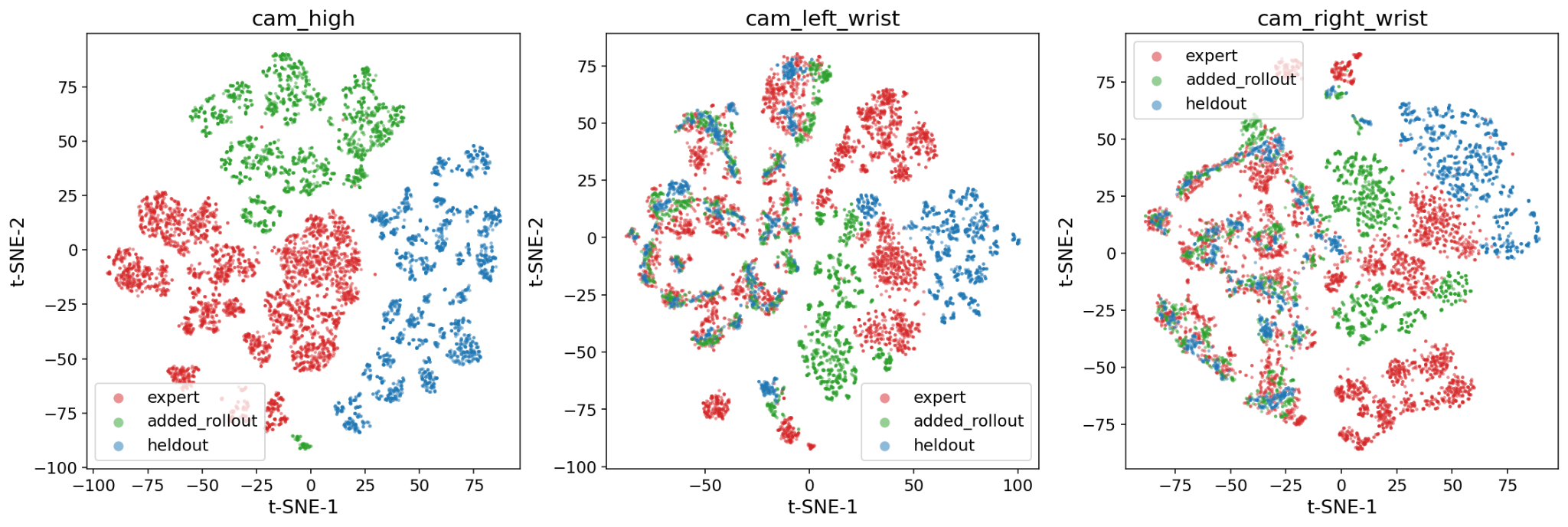
It’s not simply that more data helps. The 56 runs are a small fraction of the total training dataset, yet they more closely match our system’s working conditions than the larger set of human demonstrations.
The trade-off
While our approach has shown success in this instance, it is worth noting that, when training physical AI models only on successful runs, the model sees a narrower range of situations than it would from diverse human demonstrations. This can reduce the system’s robustness in edge cases it encounters infrequently. It remains to be seen how much training data we would need to add and how many flywheel cycles we would need to apply before seeing diminishing returns or performance degradation on edge cases.
What’s next
This blog covered a single cycle of the flywheel. Because the loop only requires our physical AI system to own runs and a light human filtering pass, the same approach can be extended to additional meals and, through cross-embodiment transfer, to other robot platforms.
The bigger opportunity is scale. Our robots operate in commercial food manufacturing facilities every day and have already generated the largest real-world dataset of food manipulation in production. Applying the same flywheel to our production data is how our Food Foundation Model (FFM) will strengthen and generalize beyond any single meal or facility.
If you’re considering physical AI for your production facility or commercial kitchen, get in touch with our team.
Contributors
Inkyu Sa, Luis Rayas, Konstantin Stulov, Xiaoyi (Sherry) Chen, Somudro Gupta, Kartheek Chandu, Tina Kao, Nick LaBounty, Krishna Teja
.jpg)

.jpg)